Tokenization Drift: Why Your AI Model Suddenly Fails and How to Prevent It
Imagine a model that performs flawlessly one moment and then inexplicably deteriorates the next, with no changes to your data, pipeline, or logic. The culprit is often surprisingly subtle: how your input gets tokenized. Before any text reaches the model, it's converted into token IDs. Even tiny formatting differences—such as spacing, line breaks, or punctuation—can yield completely different token sequences. This phenomenon is called tokenization drift: small surface-level alterations push your input into a different region of token space, causing unpredictable shifts in model behavior. In this article, we'll explore what tokenization drift is, why it happens, and how you can measure and fix it.
- What exactly is tokenization drift?
- How does tokenization drift affect model performance?
- Can you show an example of tokenization artifacts?
- Why does a leading space change token IDs so dramatically?
- How can we measure tokenization drift across prompts?
- What is a prompt optimization loop to fix drift?
- How can developers avoid tokenization drift in practice?
1. What exactly is tokenization drift?
Tokenization drift occurs when minor formatting changes in your input text lead to a different sequence of token IDs after tokenization. Models rely on token IDs to process text; even a single altered token can shift the entire semantic space the model interprets. For example, adding or removing a space before a word can split a single token into two or merge two tokens into one. This drift is particularly insidious because the input appears the same to a human reader—it's still the same words and meanings—but the model sees a mathematically different input. The result is that the model's output may change unpredictably, even though the underlying task is identical.
2. How does tokenization drift affect model performance?
The impact goes beyond just different token IDs. During instruction tuning, models learn not only tasks but also the structure in which those tasks are presented—specific separators, prefixes, and formatting patterns. When your prompt deviates from these learned patterns, you're no longer operating within the model's familiar distribution. The model isn't confused; it's doing its best on inputs it was never optimized to handle. This can lead to unexpected performance drops, reduced accuracy, or erratic outputs. For production systems, tokenization drift is a hidden source of instability that can undermine reliability and trust.
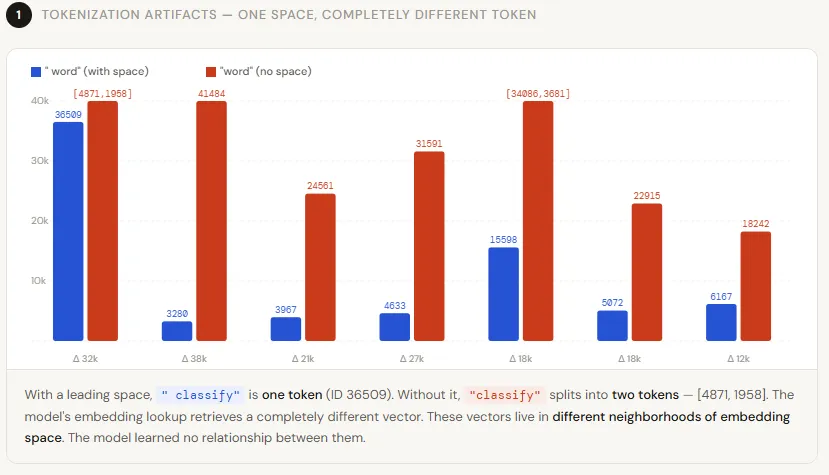
3. Can you show an example of tokenization artifacts?
Absolutely. Let's use the GPT-2 tokenizer, which uses Byte-Pair Encoding (BPE) like GPT-4, LLaMA, and Mistral. Take seven common words and test them in two forms: with a leading space and without. Encode them with add_special_tokens=False. The results are striking: not a single pair produces the same token ID. For instance, "classify" becomes two tokens [4871, 1958], while " classify" is a single token [36509]. This means the model doesn't just see a different ID—it sees a different sequence length, which shifts how attention is computed for everything that follows. Such artifacts can cascade through the entire generation process.
4. Why does a leading space change token IDs so dramatically?
Modern tokenizers like GPT-2's BPE treat spaces as part of the tokenization process. When a word has a leading space, the tokenizer merges that space with the following characters into a single token. Without the space, the first character is often merged differently. This is an intentional design: by preserving space information, the model can better understand word boundaries and syntax. However, it makes tokenization highly sensitive to formatting. The model learns that "classify" and " classify" are contextually different, because during training, words with and without leading spaces appear in different positions (e.g., start of sentence vs. mid-sentence). Consequently, tokenization drift exploits this sensitivity.
5. How can we measure tokenization drift across prompts?
We can build a simple metric to quantify drift. For a set of prompts, encode each using the tokenizer and record the sequence of token IDs. Then, define drift as the average pairwise Hamming distance between token sequences—i.e., the fraction of positions where tokens differ when aligned. Alternatively, use Jaccard similarity on the set of tokens. A higher distance indicates greater drift. You can also project token embeddings into a lower-dimensional space (e.g., via PCA) and measure the variance in the embedding coordinates across prompts. Prompts that are semantically identical but have different formatting will show large variance, flagging potential drift. This metric helps you identify which formatting choices cause instability.
6. What is a prompt optimization loop to fix drift?
Once you can measure drift, you can implement a lightweight prompt optimization loop. The idea is to test multiple formatting variations of the same prompt (e.g., with/without spaces, different line breaks, trailing newlines) and select the format that minimizes drift—ideally, one that keeps token sequences consistent. You might run a grid search over common separator patterns, prefixes, and spacing conventions. For each candidate, compute the tokenization drift metric against a baseline prompt. Choose the variant that yields the lowest drift score. This is a low-cost, pre-processing step that can significantly improve model reliability without retraining. The loop can be automated and integrated into your pipeline.
7. How can developers avoid tokenization drift in practice?
Here are actionable tips:
- Standardize prompt templates: Use consistent spacing, line breaks, and separators. Avoid trailing spaces or unnecessary punctuation.
- Validate tokenization: Build unit tests that encode prompts and compare token sequences against expected outputs.
- Monitor drift in production: Log token counts and sequence lengths; sudden changes may indicate drift.
- Use tokenizer-aware libraries: Some libraries (e.g.,
transformers) handle spaces automatically—always use them. - Pin tokenizer version: Tokenizer updates can change drift behavior; version-controlled.
- Run optimization loops: When deploying new prompts, run the drift metric and optimization loop described above.
By being proactive, you can prevent tokenization drift from undermining your model's performance.